- AI.News.Daily Newsletter
- Posts
- NVIDIA's Latest Breakthrough: The Most Powerful AI Chips Ever
NVIDIA's Latest Breakthrough: The Most Powerful AI Chips Ever
How the New B200 GPU and GB200 Superchip Are Changing the Game
AI.News.Daily
March 19, 2024
👋 Hey and welcome to AI News Daily.
Each week, we post AI Tools, Tutorials, News, and practical knowledge aimed at improving your life with AI.
Read time: 3 minutes
At the GTC conference, NVIDIA CEO Jensen Huang introduced groundbreaking technologies tailored for the generative AI era, emphasizing the transformative power of AI across industries.
NVIDIA's announcement of the Blackwell B200 GPU and GB200 superchip marks a significant milestone in AI computing, presenting what is described as the "world's most powerful chip" for AI tasks.

Image: Nvidia
These developments are pivotal for understanding NVIDIA's current technological edge and strategic positioning in the AI hardware market.
The key announcements included:
Unprecedented AI Computing Power: The Blackwell B200 GPU and GB200 superchip significantly elevate performance benchmarks, offering up to 20 petaflops of FP4 computing power and a 30-fold enhancement in LLM inference workload efficiency over previous models.
Cost and Market Accessibility Challenges: Despite their groundbreaking capabilities, the high cost—potentially 4-5 times that of the H100 model—and prioritized distribution to major cloud providers like Amazon and Google may limit access for many potential users.
Delayed Availability for Broader Market: The wider availability of consumer versions of Blackwell technology is not expected until 2025, indicating a period of anticipation for smaller entities and individual consumers.
Thanks for reading AI News Daily! Subscribe for free to receive new posts and support my work.
Blackwell B200 GPU and GB200 Superchip Overview
Performance Benchmarks: The B200 GPU alone boasts 20 petaflops of FP4 computing power, supported by its 208 billion transistors. When combined into the GB200 configuration—two B200 GPUs with a Grace CPU—the performance for Large Language Model (LLM) inference workloads is enhanced by 30 times compared to NVIDIA's previous H100 model. This leap in efficiency is also matched by a reduction in both cost and energy consumption, offering up to a 25x improvement over the H100.
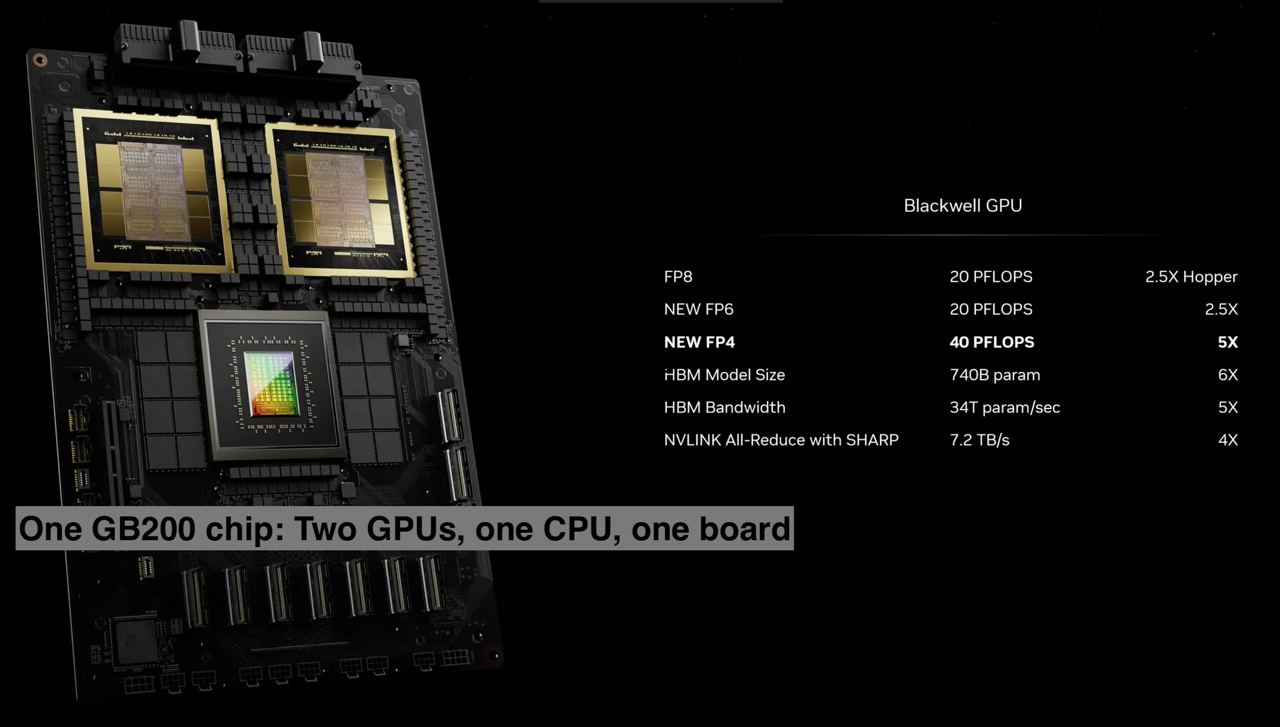
Image: Nvidia
Energy Efficiency and Cost Reduction: Training a model with 1.8 trillion parameters, which would have previously required 8,000 Hopper GPUs and 15 megawatts of power, can now be achieved with just 2,000 Blackwell GPUs, consuming only four megawatts. This showcases NVIDIA's commitment to more sustainable and cost-effective computing solutions.
Training Speed and Communication Efficiency: The GB200 superchip is said to offer four times the training speed of its predecessor, the H100. A significant part of this improvement is attributed to a next-gen NVLink switch, facilitating communication between up to 576 GPUs at 1.8 terabytes per second of bidirectional bandwidth. This enhancement addresses the previous inefficiency where clusters of 16 GPUs spent 60% of their time in communication overhead, reducing actual computation time.
Networking and Integration
Innovative NVLink Switch: To support the enhanced communication between GPUs, NVIDIA developed a new network switch chip with 50 billion transistors, capable of 3.6 teraflops of FP8 computing power. This switch is crucial for reducing communication overhead among GPUs, thus optimizing overall computing performance.
Scalability: NVIDIA's strategy involves not just individual chips but an ecosystem designed for scalability. The GB200 NVL72 configuration, for example, integrates 36 CPUs and 72 GPUs into a liquid-cooled rack, achieving up to 1.4 exaflops (1,440 petaflops) of inference performance. This setup can support models with up to 27 trillion parameters, highlighting NVIDIA's vision for handling future AI model complexities.

The GB200 NVL72. Image: Nvidia
Industry Adoption and Future Prospects
Cloud Service Integration: Major cloud service providers like Amazon, Google, Microsoft, and Oracle have plans to incorporate NVL72 racks into their offerings. This indicates a strong market acceptance and the potential widespread availability of NVIDIA's technology for cloud-based AI computations.
DGX Superpod Configuration: For even larger scale deployments, NVIDIA's DGX Superpod for DGX GB200 combines 288 CPUs, 576 GPUs, and 240TB of memory, delivering 11.5 exaflops of FP4 computing. This superpod exemplifies NVIDIA's capability to cater to the most demanding AI research and commercial applications, with scalability extending to tens of thousands of GB200 superchips interconnected with advanced networking solutions like Quantum-X800 InfiniBand and Spectrum-X800 ethernet.

Image: Nvidia
Conclusion
NVIDIA just rolled out their Blackwell B200 GPU and GB200 superchip, and let me tell you, they're nothing short of revolutionary. They are setting new records in speed, efficiency, and the ability to scale up like never before. It's like NVIDIA has taken the lead in a race we didn't even know we were running, pushing the boundaries of what AI can do for us across the board.
They're not just about crunching numbers faster; they're about making AI research and projects everywhere a bit greener and more powerful, all while keeping an eye on building a system that grows with our needs. With these advancements, NVIDIA is showing us they're not just in the game but playing to win, tackling the big questions of how we'll meet the skyrocketing demands of AI's future.
PS: I curate this AI newsletter every week for FREE, your support is what keeps me going. If you find value in your reading, share it with your friends by clicking the share button below!